×
![]()

NewraLab (苏州拟界智能科技有限公司) is an R&D laboratory based in Suzhou, China, dedicated to advancing AI for low-resource and underrepresented environments. Our research operates at the intersection of computer vision, NLP, and multimodal learning, specifically targeting domains where conventional AI struggles due to data scarcity or limited infrastructure.
We prioritize the development of efficient alternatives to Transformer architectures, utilizing state-space systems and physically grounded dynamical models. We are committed to open-source contributions that democratize high-performance AI, ensuring robust intelligence is accessible regardless of compute constraints.
A collection of lightweight visual backbone models designed for deployment on resource constrained devices in regions with limited cloud access.

We investigate state-space and dynamical-system–based alternatives to Transformer architectures, modeling dependencies with linear computational complexity.

Modeling multimodal data as interacting dynamical fields within a unified system for robust learning under noisy or sparse conditions.

Optimizing high-performance systems for deployment in emerging regions with limited compute and data infrastructure.
Yunusa H., et al. 2025| ICCV 2025. Workshop
Distilling cross-modal capabilities into linear-complexity architectures for edge devices.
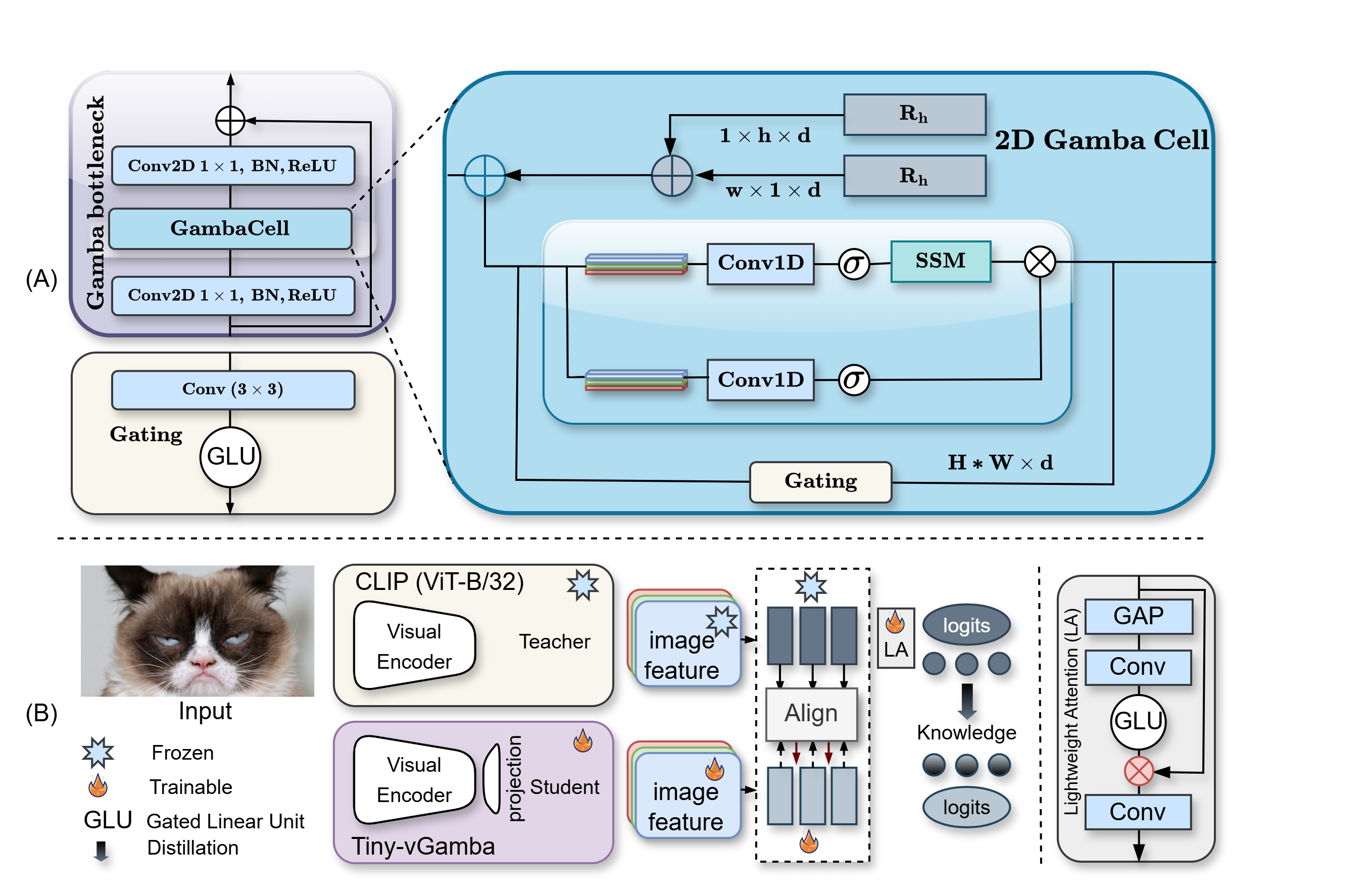
Yunusa H. et al., 2026 | Transactions on Machine Learning Research (TMLR)
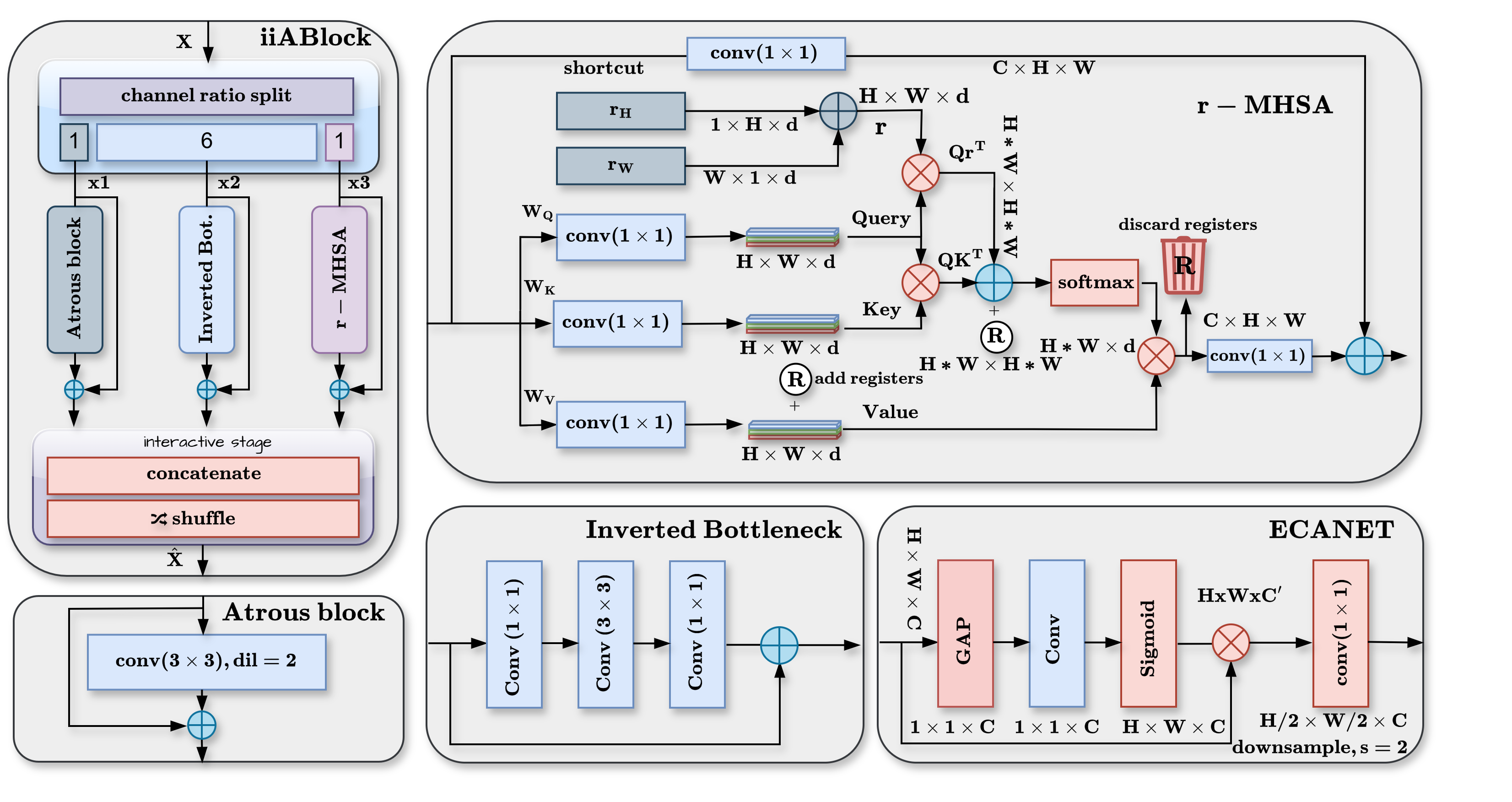
Designing iiANET: A lightweight hybrid CNN–Attention backbone for efficient long-range dependency modeling in complex vision tasks..

Founder & Lead Researcher
Computer Vision, Deep Learning and An Entrepreneur

Researcher & Developer
NLP, Sentiment Analysis

Business Lead